X-Fonter 14.0
Unicode Character Map
The Unicode Character Map is the fourth tab of the Font Detail Panel. Where the ASCII Character Map shows only the 256 characters in the ANSI range, this tab exposes the font's full Unicode coverage — up to 65,536 characters spanning every script and symbol set the font supports.
Unicode organises characters into named blocks (sometimes called pages or ranges), each covering a related group: Basic Latin, Greek, Cyrillic, Arabic, CJK Unified Ideographs, Mathematical Operators, Emoji, and many more. The map lets you jump directly to any block and see exactly which characters the selected font can render — and which it cannot.
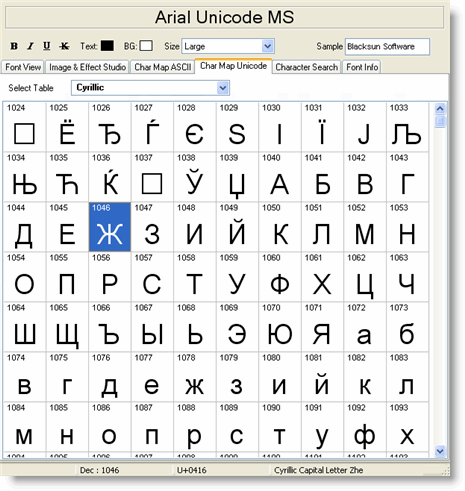
Selecting a Unicode Block
The dropdown or list directly above the character grid lets you choose which Unicode block to display. Blocks that the current font supports are shown in bold; unsupported blocks are listed in normal weight. This gives you an instant overview of a font's language and symbol coverage without having to open each block individually.
At the bottom of the list is a Show All Characters option, which loads all 65,536 code points into a single scrollable grid. This is useful for a comprehensive visual scan of everything a font contains, but can be slow to load for large fonts with extensive coverage.
Reading the Grid
The grid displays all characters in the selected block, one per cell, rendered in the current font at the preview size set in the Control Panel. Characters the font supports appear as normal glyphs; characters it does not support appear as empty cells or a generic fallback box.
When the font size is set to 20 or higher, each cell also shows the character's hexadecimal code point in its upper-left corner, making it easy to identify specific characters without counting through the grid. The column count adjusts automatically to fill the available width, so scrolling is always vertical only.
The Statusbar
Clicking any character cell selects it and updates the statusbar at the bottom of the screen with four pieces of information:
| Field | Description |
|---|---|
| Keyboard shortcut | The key combination for entering this character in Windows applications, where one exists. For many Unicode characters beyond the Basic Multilingual Plane, no single Alt+numpad shortcut is available — in those cases copy-and-paste from the map is the most practical method. |
| Decimal value | The character's Unicode code point expressed in base 10 (for example,
9786 for the smiley face ☺, U+263A). |
| Hexadecimal value | The same code point in base 16 — the standard Unicode notation (for example,
0x263A). This is the value used in HTML entities
(☺) and CSS escape sequences (\263A). |
| Character name | The official Unicode name of the character (for example, WHITE SMILING FACE). This is the same name used in the Character Search tab — if you spot a character here and want to find it in other fonts, search by this name directly. |
Copying Characters to the Clipboard
Double-click any character cell to add it to the Sample edit box above the grid. You can double-click multiple characters in sequence to build up a string. Once your characters are in the Sample box:
- Select the text in the Sample box (click and drag, or Ctrl+A).
- Right-click and choose Copy, or press Ctrl+C.
- Switch to your document and paste with Ctrl+V.
This works for any Unicode character, including CJK ideographs, Arabic letters, mathematical symbols, and emoji — even characters that have no keyboard shortcut and cannot be typed directly.
Adjusting the Display Size
The preview size is set in the Control Panel and applies across all detail tabs simultaneously. In the Unicode map:
- At smaller sizes (below 20 pt) more characters fit on screen at once and the code-point overlay is hidden — useful for a quick block-level scan.
- At larger sizes (20 pt and above) each cell is bigger, the hex code point appears in the corner, and glyph details such as stroke direction and diacritic placement become clearly visible — useful for closely inspecting a specific script or symbol.
Unicode Map vs. ASCII Map
Use the ASCII Character Map when you need to check basic Latin characters, common punctuation, or extended ANSI characters (codes 0–255), or when you need to see how the active Windows codepage affects character positions in that range.
Use the Unicode Character Map when you need to check coverage beyond the ANSI range — foreign scripts, technical symbols, mathematical notation, arrows, currency signs, or any character with a code point above U+00FF.
Related Topics
- ASCII Character Map — browse the 256 ANSI characters and check codepage effects
- Character Search — find any Unicode character by name or code point
- Image & Effect Studio — render characters from the Sample box with effects applied
- Character Encoding — background on ASCII, ANSI codepages, and Unicode and how they relate to each other
- Font Detail Panel — overview of all six detail tabs and the shared Control Panel
Copyright © 2001-2026 Blacksun Software. All Rights Reserved